
Отечественные реконфигурируемые суперкомпьютеры
Уже 15 лет у нас в стране производятся реконфигурируемые суперкомпьютеры, но только сейчас появилась возможность рассказать о них благодаря статье Сергея Шаракшанэ. Дополню текст автора фотографиями и примечаниями для популяризации материала. Этого так не хватает нашим отечественным научным статьям!

Если страна хочет обеспечить национальную безопасность, создать конкурентоспособную продукцию, предложить инновации завтрашнего дня — то сегодня ей нужно лидировать в супервычислениях. Нужно участвовать в гонке передовых государств мира по созданию все более высокопроизводительных суперкомпьютеров. Вместе с тем, в самой этой гонке возникли принципиальные трудности, и теперь создателям суперкомпьютеров сейчас нужны новые решения. Один из таких оригинальных подходов предложили российские ученые из Таганрогской школы во главе с член-корр. РАН Игорем Каляевым.
С этим подходом, как выразился академик А.С. Бугаев, мы оказались «впереди планеты всей». И хотя он не позволяет кардинально решить все проблемы современных вычислительных систем — это сейчас никому в мире не по силам, — он позволяет повысить основные характеристики на один-два-три порядка при решении ряда актуальных научно-технических задач. Речь идет о так называемых реконфигурируемых компьютерах. И 12 мая с.г. Президиум РАН заслушал научное сообщение «Многопроцессорные вычислительные и управляющие системы с реконфигурируемой архитектурой» члена-корреспондента Игоря Анатольевича Каляева, директора НИИ многопроцессорных вычислительных систем Южного федерального университета.
* * *
Итак, суть подхода Таганрогской школы в следующем: у суперкомпьютера есть временны́е затраты, связанные с организацией вычислительного процесса и с ними надо бороться, так вот, ученые предложили их минимизировать путем создания специализированной многопроцессорной вычислительной системы. Грубо говоря, отказаться от стремления к универсальности машины, а наоборот — конкретно под задачу сконструировать такую конфигурацию суперкомпьютера, которая наиболее подходит именно под данный тип задач. И выигрыш на этом пути оказался огромным, поскольку множество важнейших задач, имеющих для страны стратегическое значение, как раз оказались такими: они потребовали бы колоссальной, почти нереальной на сегодня производительности суперкомпьютеров, но суперкомпьютеры, созданные с конфигурацией строго под данные узкие классы задач, будучи на порядки более экономичными, с блеском с данными задачами справляются.
* * *
Какова в настоящее время основная тенденция в мире в области супервычислений?
Член-корреспондент И.А. Каляев. Если с 1964 г. по 1984 г. производительность суперкомпьютеров повысилась на три порядка, то дальше каждые десять лет производительность повышалась именно на эти три порядка. Список ТОП-500, который включает в себя 500 наиболее производительных вычислительных систем мирового сообщества, обновляется два раза в год. Сегодня первое место занимает китайский суперкомпьютер «Тианхэ-2» («Млечный путь») с производительностью 33,9 петафлопс, то есть 1015 операций в секунду. Далее идут два американских суперкомпьютера — «Titan» Оук-Риджской национальной лаборатории и «Sequoia» Ливерморской лаборатории.
Суперкомпьютеры, занимающие первые места в этом списке ТОП-500, потребляют очень много электроэнергии — около 10 мегаВатт, а суперкомпьютер «Тианхэ-2», занимающий первое место, потребляет почти 18 мегаватт!
Для достижения же экзафлопсной производительности при использовании современных технологий потребуется предположительно 1 гигаватт мощности (это примерно шестая часть энергии, даваемой Саяно-Шушенской ГЭС) и потребуется 250 тысяч кубических метров объема оборудования (это здание с основанием 50 на 50 метров и высотой в 100 метров). Не решены также и принципиальные проблемы с отводом тепла.
В действительности ситуация еще хуже. Большинство
суперкомпьютеров, входящих в список ТОП-500, имеют жесткую
кластерную архитектуру. Компьютеры данного класса показывают
высокую производительность при решении только так называемых
связанных задач, которые не требуют большого числа информационных
обменов —
Более того, спад производительности наблюдается и при увеличении
числа процессоров в системе. В жесткой архитектуре таких систем
возникают большие непродуктивные временны́е затраты, связанные не с полезными вычислениями, а с организацией вычислительного
процесса: часть процессоров простаивает, часть занимается
транзитом информации — все это ведет к большим временны́м потерям
при организации вычислительного процесса. В качестве
примера можно привести задачу моделирования и оптимизации режимов
работы газотурбинного двигателя: даже с использованием
суперкомпьютера производительностью 1 петафлопс (что эквивалентно
производительности суперкомпьютера «Ломоносов»), необходимо 2,5
тысячи дней машинного времени,
Академик Б.Н. Четверушкин. Производительность, если вы берете много процессоров или ядер, резко падает, получается — машина есть, а с решением больших задач возникает проблема. С этим сейчас столкнулись наши зарубежные партнеры. В конце апреля на одной конференции мы беседовали с директором китайского центра: у них к концу года будет машина 100 петафлопс, но — как использовать? Та же самая проблема в Штутгарте. Когда одновременно работает сотня тысяч ядер, они мешают друг другу.
Словом, исследователи в области суперокомпьютеростроения подошли к некоторому технологическому пределу.
* * *
Вывод: нужны новые подходы к созданию высокопроизводительных вычислительных систем.
Академик Ф.Л. Черноусько. Игорю Анатольевичу принадлежит новый, оригинальный подход к построению компьютеров, который он называет «реконфигурируемыми системами», который дает возможность пользователю программировать архитектуру компьютера под структуры решаемой задачи. Этот проблемно-ориентированный подход дает большой выигрыш.
Академик А.С. Бугаев. Сделан, по сути дела, завод по производству спецкомпьютеров, которые широко востребованы для различных применений — они по своим параметрам на порядки превосходят универсальные спецвычислители, поэтому имеют огромную нишу для применений.
Академик В.Г. Бондур. Обычно суперкомпьютеры созданы по т.н. кластерной архитектуре, когда берутся микропроцессоры, коммутаторы и собираются для решения кластерных задач. И слабосвязанные задачи, по терминологии Игоря Анатольевича, решаются отдельно на каждом кластере.
Мы, как математики, идем другим путем: стараемся создать логически простые, но эффективные алгоритмы. Это крайне сложно, но во многих случаях получается. У нас сейчас есть примеры расчетов вместе с коллегами из Таганрога — на миллиардах узлов и полных трехмерных задач астрофизики с магнитной гидродинамикой, полные трехмерные задачи гидродинамики.
* * *
О преимуществах «реконфигурируемых систем».
Академик В.Г. Бондур. Это, во-первых, высокая производительность — до 60 процентов пиковой производительности может быть реализовано в этой архитектуре. Во-вторых, высокая энергетическая эффективность — количество операций на Ватт или мегаВатт энергопотребления больше, чем в случае с обычными кластерными процедурами, почти на два порядка. И, в-третьих, это маленькие объемы, которые занимает оборудование — примерно на два порядка меньше, чем у кластерных вычислительных систем.
Академик Ф.Л. Черноусько. Очень важно, что при этом улучшается и отказоустойчивость системы. Обычный способ борьбы с отказами — это резервирование, то есть создание, дублирование системы: если одна выйдет из строя, ее заменяет вторая. В подходе, который развивается И.А. Каляевым, отказоустойчивость увеличивается за счет того, что некоторые блоки в случае отказа берут на себя часть работы, которая должна быть выполнена.
Академик А.С. Бугаев. Можно было ожидать серьезных проблем с тем, как транслировать обычные программы, которые созданы для кластерных компьютеров. Но коллектив И.А. Каляева придумал замечательный язык, который позволяет создавать некий ретранслятор программ, созданных для других вычислительных систем, и превращать в системы, которые можно реализовывать на этих суперкомпьютерах — это очень важно.
* * *
Научное сообщение члена-корреспондента И.А. Каляева.
Минимизировать временные затраты, связанные с организацией вычислительного процесса в процессорной системе, можно следующим образом. В каждой операционной вершине информационного графа необходимо вставить свой вычислительный элемент и связать их друг с другом в соответствии с топологией информационного графа. В этом случае все непродуктивные затраты будут минимизированы и реальная производительность такой многопроцессорной системы практически равна пиковой, то есть теоретически достижимой.
-
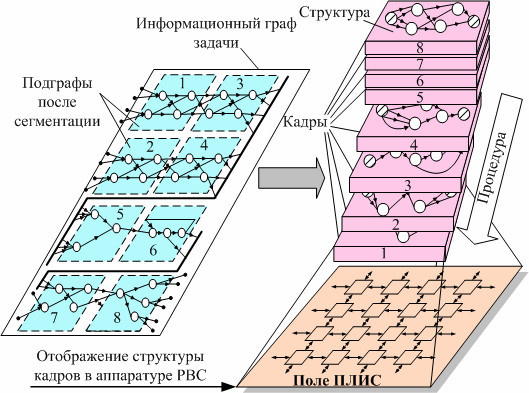
- Структурно-процедурная организация вычислений в поле ПЛИС

Понятно, что создание подобной проблемно-ориентированной вычислительной процессорной системы под каждую задачу слишком накладно. Поэтому мы предлагаем совместить преимущество кластерных многопроцессорных вычислительных систем, учитывая их универсальность, и специализированных, а именно, их высокую реальную производительность — предоставив возможность пользователю формировать архитектуру вычислительной системы.
Для этого у него должно быть в распоряжении некоторое вычислительное поле, состоящее из набора вычислительных элементов и средств коммутации между ними. Тогда при решении очередной задачи с помощью средств схемотехнического программирования пользователь может создать проблемно-ориентированную вычислительную структуру, которая адекватна решаемой задачи, и минимизирует все непродуктивные расходы.
При изменении задачи, он в рамках этого поля может создать новую структуру, которая опять-таки будет оптимальна для решения текущей задачи.
Так обеспечиваем универсальность: при решении каждой задачи за счет того, что создается проблемно-ориентированная структура, минимизирующая временны́е затраты, связанные с организацией вычислительного процесса.
Эта идея своими корнями восходит еще к аналоговым вычислительным машинам, в которых вычислительное поле состояло из набора решающих блоков, построенных на базе операционных усилителей, а коммутация между этими блоками осуществлялась вручную с помощью штекерного поля. В результате формировалась физическая модель решаемой задачи. В той или иной степени идеи реконфигурации были использованы также в цифровых интегрирующих машинах, однородных вычислительных средах, многопроцессорных вычислительных системах с программируемой архитектурой.
Тем не менее, несмотря на большое число исследований в этом направлении, до реальных масштабных внедрений дело не дошло — вследствие отсутствия элементной базы, отвечающей концепции реконфигурируемости архитектуры.
Наконец, в начале 21 века такая элементная база появилась — это так называемые ПЛИС (программируемые логические интегральные схемы) высокой степени интеграции. В настоящее время основной рынок ПЛИС занимают, в основном, две американские фирмы — фирма «Альтера» и фирма «Ксайленкс».
С помощью таких ПЛИС строится вычислительное поле путем
их объединения в некоторую структуру, например —
ортогональную решетку. В рамках этого поля каждый раз будет
формироваться проблемно-ориентированная структура, которая
наилучшим образом отвечает структуре решаемой задаче.
Чем больше будет такое вычислительное поле, тем проще будет отображать его вычислительные задачи без необходимости разрезания их на подзадачи. Поэтому в конструктивном исполнении такое вычислительное поле предлагается формировать на основе т.н. «базовых модулей», каждый из которых включает в себя некоторое количество ПЛИС и представляет фрагмент общего вычислительного поля ПЛИС.
-

- Базовый модуль 16М50 Медведь, 2006 год

Эти базовые модули дальше собираются в реконфигурируемые вычислительные блоки,
-

- Вычислительный блок Медведь, 2006 год

дальше — в вычислительные стойки,
-

- РВС-1Р - Мицар, 2008 год

и все это завязывается в единый вычислительный ресурс. Иными словами: в системе отсутствуют стандартные процессоры — весь ресурс ПЛИС используется как один огромный процессор, в рамках которого можно формировать любые вычислительные структуры под решаемые задачи.
Мы развиваем эту технологию более 15 лет и на основе этой технологии создали большое количество различных систем. В качестве примера приведу базовый модуль 2013 года — он включает восемь ПЛИС, каждый из которых содержит 58 млн. вентилей. Все это завязано в общий вычислительный ресурс, в рамках которого можно разместить 1 300 параллельно работающих процессоров. Производительность такой платы составляет 70 гигафлопс или 700×109 операций в секунду при потребляемой мощности 300 Ватт (Информацию по данному модулю я не смог найти в интернете. Скорее всего автор назвал очень приблизительную цифру в производительности.)
Это — достаточно сложная технология. Такая плата содержит более 20 слоев. Каждая такая ПЛИС имеет около 2 тыс. «ножек». Это т.н. БГА-корпус, то есть ножки расположены снизу в виде шариков. ПЛИС надо очень точно разместить на плате, прежде чем паять, потом идет сложная технология пайки. Тем не менее, вся эта технология нами освоена, она работает в нашей стране — платы разрабатываются в стране, сборка происходит в стране, настройка — в стране, единственное, к сожалению, сами чипы — зарубежные.
Здесь показан один из первых таких комплексов, созданный в 2009 году — он стоит в МГУ.
-

- РВС-5 Бенетнаш, 2009 год

-

- РВС-5 Бенетнаш, 2009 год

Он построен на основе
-

- Базовый модуль 16V5-75 Алькор (Большая медведица), 2008 год

Здесь задействовано одновременно более 1200 ПЛИС (1280) и в этом вычислительном поле размещается более 25 тыс. параллельно работающих процессоров. (РВС-5 состоит из пяти стоек РВС-1. Параметры стойки: 1 ТФлопс двойной точности, 4,8 кВт, 0,21 ГФлопс/Вт, 0,99 ТФлопс/м3)
Еще пример — реконфигурируемая система 2011 года.
-

- Базовый модуль Ригель, 2011 год

-

- Вычислительный блок Ригель, 2011 год

-

- Стойка на основе вычислительных блоков Ригель, 2011 год

Всего в вычислительном поле задействовано более 1100 ПЛИС, общее число размещаемых процессоров — 130 тыс. параллельно работающих процессоров, производительность — 51 терафлопс (одинарной точности) или 51×1012 при потребляемой мощности всего 50 кВт. (Параметры стойки: 16,2 ТФлопс двойной точности, 50,4 кВт, 0,32 ГФлопс/Вт, 17,98 ТФлопс/м3)
Система «Орфей» для цифровой обработки сигналов (о ней я еще скажу более подробно) имеет производительность 6,5×1014(Система предназначена для обработки телекоммуникационных данных, например шифрование или мониторинг потоков и состоит из двух стоек. В ней были применены оптические каналы. Параметры стойки: 16 ТФлопс двойной точности, 10 кВт, 1,6 ГФлопс/Вт, 23,3 ТФлопс/м3)
-

- Базовый модуль Орфей, 2011 год

-

- Вычислительный модуль Орфей, 2011 год

-

- РВС Орфей-Т, 2011 год

Реконфигурируемая система РВС-7 (2013 год) содержит 864 ПЛИС, производительность 1,5×1015 операций в секунду при потребляемой мощности 50 кВт (Параметры стойки: 29,4 ТФлопс двойной точности, 50 кВт, 0,59 ГФлопс/Вт, 29,16 ТФлопс/м3)
-

- Базовый модуль 6V7-180 Плеяда, 2013 год (не вырезана из текстолита)

-

- Вычислительный блок 24V7-750 Плеяда, 2013 год

-

- РВС-7, 2013 год

Для сравнения: суперкомпьютер «Ломоносов» (использует процессоры Xeon X5570/X5670/E5630 2.93/2.53 GHz и в качестве спецвычислителей Nvidia 2070 GPU, PowerXCell 8i) потребляет около 3 мегаВатт электроэнергии, занимает 250 кв.метров площади. Эта же система — одностоечная, занимает чуть больше 1 кв.метра площадь и потребляет всего 50 кВт электроэнергии, а по производительности они практически эквивалентны, если не считать, что здесь используется фиксированная запятая.
Переход на новое поколение ПЛИС потребовал разработки принципиально новой системы охлаждения таких суперкомпьютеров. Плотность компоновки ПЛИС поколения «Вертекс-8» уже такова, что уже невозможно использовать воздушную систему охлаждения, которая была применена в предыдущих сериях таких суперкомпьютеров. Совместно со специалистами ИПС РАН нами была разработана принципиально новая технология — технология жидкостного погружного охлаждения.
То есть плата просто опускается в специальную инертную жидкость, через которую производится отвод тепла. Такой подход позволил в пять-десять раз повысить теплоотвод по сравнению с воздушной системой охлаждения. На базе этой технологии в настоящее время нами создается суперкомпьютер в одностоечном варианте, имеющий производительность 1 петафлопс при потребляемой мощности всего 154 кВт. В рамках этого суперкомпьютера задействовано вычислительное поле, содержащее 1,5 тыс. ПЛИС. (Предположительные характеристики стойки: 333 ТФлопс двойной точности, 154 кВт, 2,16 ГФлопс/Вт, 330 ТФлос/м3. На основе таких модулей можно построить суперкомпьютер с пиковой экзафлопсной производительностью двойной точности и энергопотреблением менее полгигаватта, а не один гигаватт как на зарубежных системах. При этом вычислитель в отличие от своих конкурентов будет высокопроизводительным для любых задач!)
-

- Вычислительный модуль Скат

-

- Вычислительный модуль Скат

-

- Вычислительный модуль Скат

-

- Вычислительный модуль Скат

(Только вдумайтесь в эти цифры. Производительность одного вычислительного модуля Скат около 30 ТФлопс двойной точности!!!)
Раньше в процессе программирования реконфигурируемых суперкомпьютеров необходимо было задействовать по крайней мере двух специалистов — схемотехника, который должен был формировать вычислительные структуры, адекватные решаемой задаче, и программиста, который должен был программировать ПЛИС для отображения этих структур. Но сейчас нами создан комплекс системного программного обеспечения, который позволяет полностью автоматизировать процесс программирования реконфигурируемых вычислительных систем. Задача пишется на языке высокого уровня — это наша разработка. (язык высокого уровня COLAMO)
Далее с помощью средств отображения автоматически строится граф
задачи, разрезается на подграфы в зависимости от имеющегося
вычислительного ресурса и отображается уже в вычислительное поле
ПЛИС. При этом заполняемость вычислительного поля ПЛИС составляет
не менее 60%. Иными словами реальная производительность
реконфигурируемых суперкомпьютеров при решении прикладных задач
составляет не менее 60% от пиковой,
Поскольку это — нестандартная система программирования, наиболее эффективное применение такие машины находят при решении так называемых потоковых задач, когда нужно по единому алгоритму обрабатывать большие массивы или потоки данных. В качестве примеров можно привести задачу корректировки атмосферных изображений, получаемых с помощью большого телескопа специальной Астрофизической обсерватории РАН. Наша небольшая машинка, величиной с обычный ноутбук, позволяет в реальном масштабе времени обрабатывать картинку, которая получается с телескопа, и преобразовывать ее к нужному виду для дальнейших исследований. Ускорение составляет 142 раза.


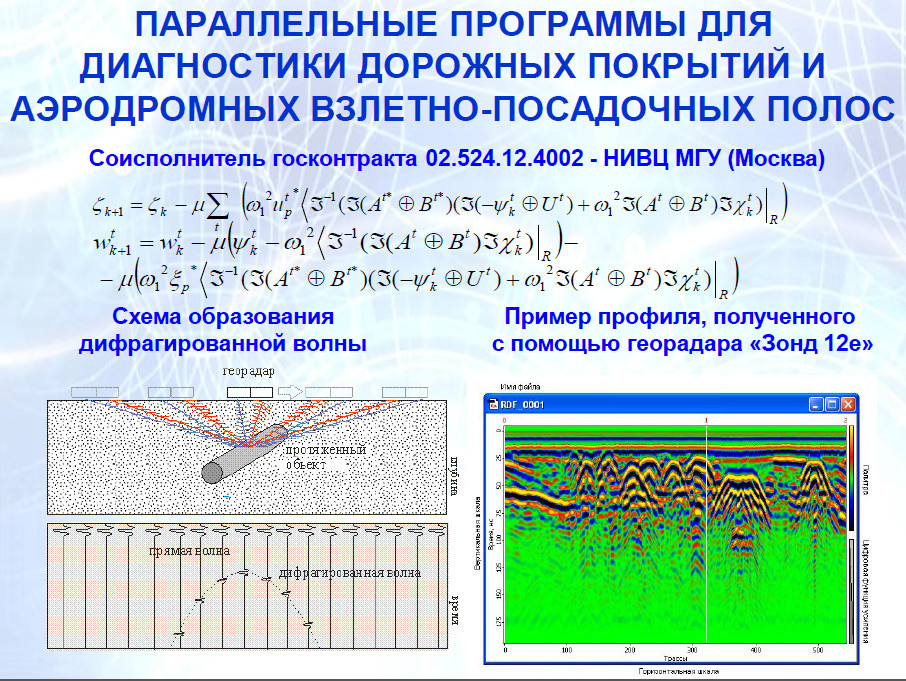
Совместно со специалистами МГУ нами была разработана система диагностики дорожных покрытий взлетно-посадочных полос. Такая небольшая машинка, установленная непосредственно в автомобиле, в реальном масштабе времени обрабатывает данные, получаемые от георадара, строит трассы радарограмм и формирует соответствующую информацию. Ускорение по сравнению с обычной системой составляет около 200 раз.
Хорошие перспективы использования таких реконфигурируемых вычислительных систем в бортовых комплексах — их обеспечивают высокие технические характеристики соотношений производительности к объему и производительности к потребляемой мощности.
Принцип реконфигурации может быть использован не только для повышения вычислительных характеристик многопроцессорных вычислительных информационных и управляющих систем, но и для повышения их отказоустойчивости.
В настоящее время проблема отказоустойчивости решается, в основном, за счет принципа резервирования, то есть в состав системы вводится несколько дополнительных процессорных узлов, находящихся в резерве, и в случае выхода из строя любого процессорного узла его задача переносится на один из резервных узлов. Однако понятно, что введение в состав системы дополнительных резервных узлов приводит к повышенному энергопотреблению, повышенным габаритам системы, что зачастую недопустимо, особенно в случае работы таких систем в мобильном варианте.
Поэтому нами предложен способ, позволяющий повысить отказоустойчивость таких сетевых информационно управляющих систем без дополнительных аппаратурных затрат, только за счет их реконфигурации. Идея заключается в следующем. Каждый процессорный узел системы имеет некоторый резерв производительности. Под резервом производительности понимаем возможность выполнения большего объема вычислений в отведенный промежуток времени, чем задана ему в соответствии с изначальным распределением подзадач, общей задачей управления по процессорам.
Тогда в случае выхода из строя любого процессорного узла мы можем перенести задачи, которые решал этот процессорный узел, на работоспособные процессорные узлы, не выходя за ограничения по лимиту времени. При этом преимуществом такого подхода является то, что мы не вводим в состав системы никакого дополнительного оборудования. Обеспечиваем отказоустойчивость только за счет реконфигурации системы. Показано, что метод реконфигурации по сравнению с методом резервирования обеспечивает большую вероятность безотказной работы таких многопроцессорных информационно управляющих систем, причем потребление уменьшается, а число парируемых отказов не увеличивается.
Кто должен осуществлять мониторинг работоспособности всех процессорных узлов и выполнения процедуры реконфигурации? В простейшем случае это можно поручить некоторому специально выделенному процессорному узлу, играющему роль центрального диспетчера. Но тогда эта система становится неустойчивой: выход из строя «центрального диспетчера» будет приводить к отказу системы в целом. Поэтому нами разработан новый подход, использующий множество программных агентов, размещенных в процессорных узлах. Каждый такой программный агент отслеживает работоспособность процессорного узла, в котором он расположен, и информирует об этом всех остальных программных агентов.
Если в какой-то момент времени программный агент перестал отвечать на запросы других программных агентов, они понимают, что соответствующий процессор вышел из строя, и предпринимают шаги по реконфигурации, то есть по переразмещению задач, возложенных на этот процессорный узел, на работоспособные узлы. При этом в состав системы не вводится никакое дополнительное оборудование, и, соответственно, вероятность безотказной работы такой системы не уменьшается. Разработаны алгоритмы такой реконфигурации, они характеризуются временем реконфигурации, что эквивалентно времени восстановления вычислительного процесса, и качеством реконфигурации.
В качестве примера использования данной технологии можно привести информационно-управляющую систему транспортно-технологического комплекса перегрузки ядерного топлива на АЭС. Мы создаем такие вычислительные комплексы. Они используются и применяются на целом ряде отечественных и зарубежных атомных станций, в частности — на всех энергоблоках Ростовской атомной станции, Нововоронежской атомной станции. Эти процессоры имеют многопроцессорную сетевую архитектуру и решают комплекс задач, которые в объединенном виде показаны на данном слайде.
Использование метода реконфигурации без дополнительных аппаратурных затрат позволило увеличить количество гарантированного отказа с одного до пяти, а гамма-процентную наработку на отказ — на 56 процентов, с 1,5 до 2,5 тыс. часов.
Еще один пример — информационно-управляющая система перспективного авиационного комплекса. Эта система разрабатывается нами совместно со специалистами концерна «Вега». Использование метода реконфигурации без введения в состав системы дополнительного оборудования позволило увеличить число гарантированных отказов с одного до пяти, а гамма-процентную наработку почти на 200 процентов. При этом время реконфигурации для восстановления вычислительного процесса после обнаружения отказа составляет не более двух секунд.
Таким образом, разработаны теоретические основы и новая технология создания реконструируемых вычислительных и управляющих систем, обеспечивающие решение ряда практически важных прикладных задач обработки информации и управления, повышения их вычислительной эффективности:
— соотношение реальной пиковой производительности в пять-десять раз,
— удельной производительности, то есть производительности единицы объема, — в 100-150 раз,
— энергоэффективности производительности, на Ватт потребляемой мощности — в пять-десять раз,
— отказоустойчивости, то есть гамма-процентной наработки на отказ, — в полтора-три раза.
Пока за рубежом таких машин нет. В лучшем случае они используют ПЛИС в качестве сопроцессоров в ускорителях, а мы используем их как полный вычислительный ресурс.
Кстати, а вы знали, что на «Сделано у нас» статьи публикуют посетители, такие же как и вы? И никакой премодерации, согласований и разрешений! Любой может добавить новость. А лучшие попадут в наш Телеграм @sdelanounas_ru. Подробнее о том как работает наш сайт здесь👈
Другие публикации по теме
- Командой научно-образовательного центра Функциональные Микро/Наносистемы (Н...С не превышают 5 дБ/м в телекоммуникационном диапазоне длин волн.
- Ученые МФТИ впервые показали считывание сверхпроводникового кубита компактн... может быть использован при масштабировании сверхпроводящих квантовых схем.
- Ученые Санкт-Петербургского государственного университета и ИПМаш РАН ...характеристики перспективных наноструктурированных материалов» СПбГУ.



Поделись позитивом в своих соцсетях
Larin02.01.16 09:54:49Александр Белехов06.08.15 20:25:11Александр Белехов06.08.15 20:59:33